
Vector Search in Practice
A Deep Dive Into Vector Search, Business Use Cases and Future of Retrieval

Introduction
Hello everyone! Welcome to the final edition of my ‘In Practice’ series!
Over the past few weeks in August, we’ve explored a range of technical topics including embeddings, MCP, and quantization in practice. For this concluding issue, I’m turning the spotlight to vector search, vector databases, and their real-world business applications.
We’ll dive into the strengths and limitations of vector search, and discuss how to design smart, scalable architectures that make the most of this powerful technology.
What is Vector Search
Vector search is a powerful technique used to find similar items or data points such as words, documents, images, or videos, by representing them as vectors, also known as embeddings. These vectors are numerical representations that capture the semantic relationships between elements, making them highly effective for machine learning and AI applications.
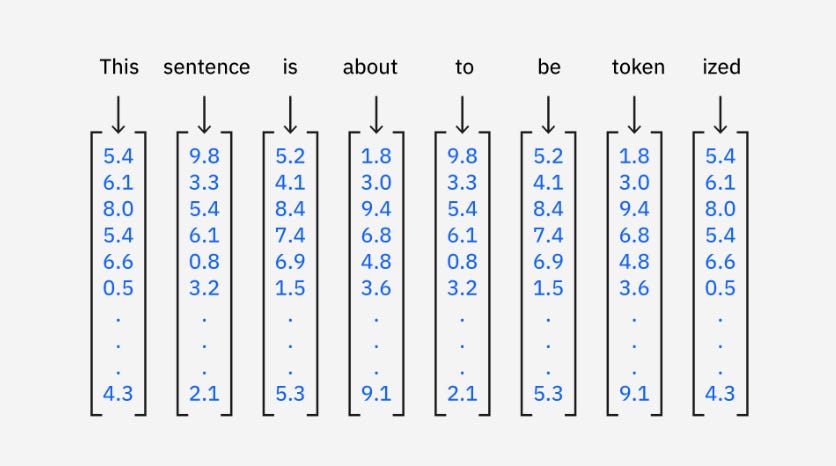
How Vector Search Works
Vectorization: Data is converted into dense vectors using models like Word2Vec or transformer-based models like BERT.
Storage: These vectors are stored in a vector database or integrated into search engines using plugins.
Indexing: Efficient retrieval is enabled by indexing techniques like Hierarchical Navigable Small World (HNSW), which cluster similar vectors together for fast search.
Querying: When a user submits a query, it’s vectorized in real-time. The system then compares this query vector to stored vectors and returns the most similar results.
Calculating Similarity in Vector Search
Once vectors are stored and indexed, the next step in vector search is to calculate similarity scores between the query vector and the stored vectors to identify the most relevant results. There are several widely used methods for measuring similarity:
Euclidean Distance: This method calculates the straight-line distance between two vectors in a multi-dimensional space. It’s computed as the square root of the sum of the squared differences between corresponding coordinates. The smaller the distance, the more similar the vectors are.
Cosine Similarity: Cosine similarity measures the angle between two vectors rather than their distance. It evaluates how closely the vectors point in the same direction, making it especially useful when the magnitude of vectors is less important than their orientation. A cosine similarity of 1 means the vectors are perfectly aligned.
Approximate Nearest Neighbor (ANN): While exact similarity calculations like Euclidean or cosine are effective, they become computationally expensive when dealing with large datasets. ANN algorithms offer a solution by finding vectors that are approximately closest to the query vector. Instead of exhaustively comparing the query against every vector in the database, ANN methods such as Hierarchical Navigable Small World (HNSW) use smart indexing and clustering to quickly narrow down the search space. This allows for fast and scalable similarity search with minimal loss in accuracy.
Vector Databases
Vector databases are specialized systems for storing and searching embeddings. Instead of matching exact keywords, they enable semantic search, retrieving results based on context and similarity. They also provide the memory layer that makes LLMs more useful in real-world applications.
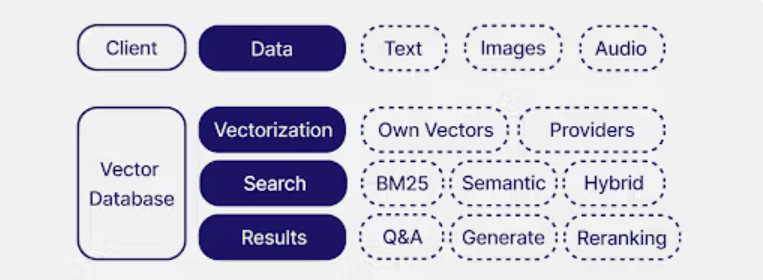
How Businesses Use Vector Databases
Businesses are adopting vector databases to make unstructured data actionable. In customer service, they power AI assistants that search knowledge bases semantically, cutting response times and improving accuracy.
In e-commerce and media, they drive personalized recommendations by matching users with products, content, or ads based on similarity rather than static rules. For enterprise AI, they are critical to retrieval-augmented generation (RAG), where LLMs are grounded in proprietary data such as policy documents, research archives, or client records, to reduce hallucinations and deliver compliant, trustworthy answers.
Popular options for vector databases include: Pinecone, Weaviate, Milvus, Qdrant, Vespa, and database extensions like Postgres pgvector and Elasticsearch.
Limitations
Research on the theoretical limits of embedding-based retrieval shows that single-vector search has inherent constraints. Because embeddings have fixed dimensionality, they can only represent a limited number of distinct top-k document combinations. This bottleneck is tied to the sign-rank of the relevance matrix and cannot be overcome just by adding more training data.
Empirical results confirm that even state-of-the-art models fail to achieve high recall on carefully designed benchmarks, and increasing embedding dimensions still caps performance. This means vector search alone cannot reliably handle all information retrieval tasks at scale.
How Applications Should Use Vector Search Efficiently
To overcome these limits, businesses and developers should treat vector databases as one part of a hybrid retrieval architecture, combining them with complementary methods for efficiency and accuracy:
Multi-vector models: Instead of compressing all semantic information into one vector, use multiple token-level vectors per document, improving recall while preserving efficiency.
Sparse retrieval : Keyword or term-frequency–based models are effective at capturing exact matches that embeddings miss, especially for domain-specific or rare terms.
Hybrid pipelines: Many production systems blend semantic search (vector DB) with sparse retrieval, followed by reranking, to maximize both coverage and relevance.
In practice, businesses should see vector databases not as a standalone silver bullet but as the fast semantic filter in a layered architecture. Hybrid systems ensure efficient retrieval, maintain high recall on complex queries, and keep enterprise AI applications robust, scalable, and trustworthy.