



How o1-like LLMs think?
LLMs like OpenAI’s o1 model, are designed to think more carefully before answering, making it better at solving complex problems. They use reflective processing, meaning it can check its own work and fix mistakes, leading to more accurate responses. Unlike previous models that predict words quickly based on probabilities, these LLMs are conditioned to take extra steps to break problems into smaller steps (chain-of-thought reasoning), similar to how a person might show their work in a math problem. These extra steps make it more like human problem-solving, where careful thoughts lead to better decisions.
This paper highlights how encouraging the model to think through a problem in more detail rather than jumping to an answer immediately (increasing reasoning steps) can improve accuracy. Improved accuracy happens because breaking down problems helps LLMs avoid shallow heuristics and instead engage in deeper logical processing.
Depth of Thought in LLMs: Understanding Thought Switching
Despite the success of these models, its important to investigate if o1-like LLMs are thinking deeply enough. A recent study explored the depth of thought in o1 like LLMs and investigated underthinking, which refers to the tendency of o1 like LLMs to prematurely abandon thoughts, leading to inadequate depth of thought.
In the paper, thoughts are described as the intermediate cognitive steps during a reasoning strategy produced by the model. Thought switching in o1 like LLMs can be observed when terms like ‘alternatively’ are used.
On average, the LLMs consume 225% more tokens in incorrect responses than in correct ones due to 418% more frequent thought switching behavior. The image below highlights an example of QwQ-32B-Preview model’s output response that consists of 25 reasoning thoughts within a single solution.

Experiments were conducted using three datasets that covered challenging math problems and multiple choice questions that covered sub-domains of physics, chemistry and biology. It was observed that o1 like LLMs generate more thoughts with increase of difficulty level, this suggests that these models switch thoughts more frequently as the complexity of the problem increases.
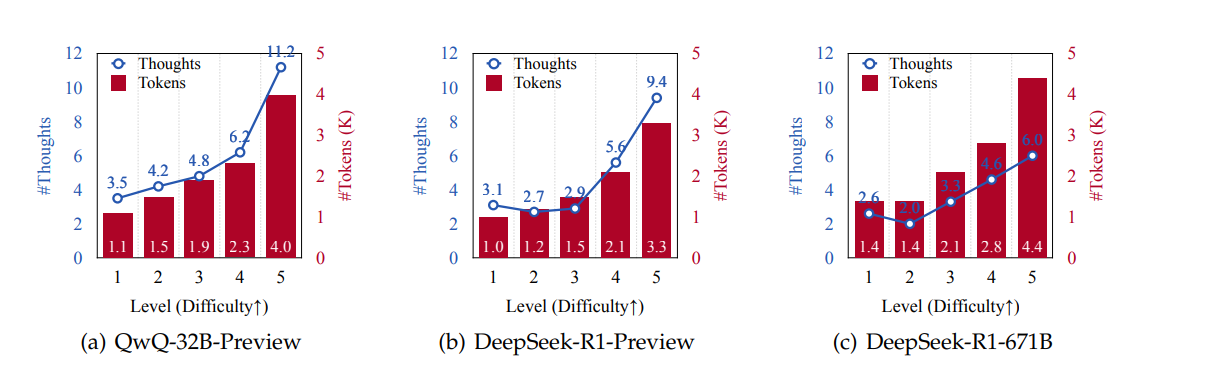
The trend from the image above highlights that while these models are designed to dynamically adjust their cognitive processes to solve problems, frequent thought switching does not lead to higher accuracy. Instead this leads to computational inefficiency.
Existence of Underthinking
Underthinking occurs when a model fails to deeply explore promising paths, instead frequently switching strategies prematurely. Some key insights from extensive analyses in the paper show that underthinking manifests itself in the following patterns:
It occurs more frequently on harder problems
It leads to frequent thought switching between different thoughts without reaching a conclusion in the each
It correlates with incorrect responses due to insufficient exploration of reasoning paths.
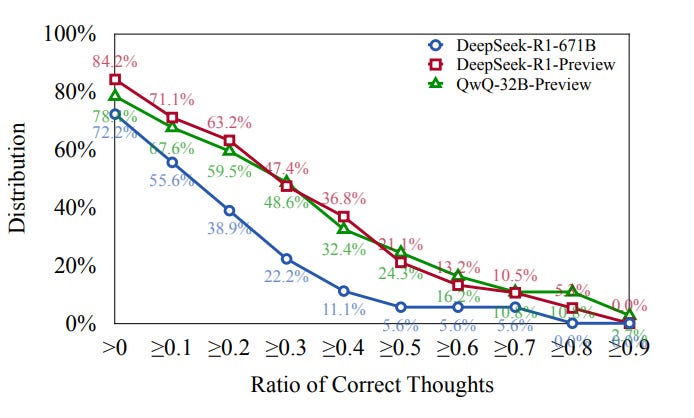
The analysis provides critical insights into the phenomenon of underthinking. Most incorrect responses contain one correct thought. This suggests that o1-like models can initiate correct reasoning pathways, they may struggle to continue these pathways to reach the correct conclusion.
Mitigating Underthinking
The findings indicate that o1-like LLMs favor many solutions rather than deeply investigating a single one. The paper introduces a novel decoding algorithm that applies a thought switching penalty (TIP) to encourage models to explore ideas more thoroughly before shifting to new ideas. To discourage premature thought transitions, TIP is applied to tokens associated with switching (e.g., alternatively).
Modifying Standard Decoding to Encourage Deeper Reasoning
Standard decoding refers to the default process an LLM uses to generate text by selecting tokens sequentially based on their probabilities. Token probabilities at each position are computed via a softmax function over the logits, generating sequences based on these probabilities. The model then selects a token using a specific decoding strategy as greedy decoding, beam search, nucleus sampling, etc. Standard decoding is used whenever LLMs generate text. It is important in tasks where the sequence of generated tokens determines fluency, coherence, and reasoning accuracy.
However, standard decoding does not regulate thought transitions which can lead to underthinking. To address this, modifications like the Thought Switching Penalty (TIP) can be introduced to encourage deeper exploration of thoughts before moving on to new ones.
Towards Adaptive Thought Regulation in LLMs
Empirical results demonstrate that TIP reduces underthinking and improves reasoning performance. Looking ahead, future work could explore adaptive mechanisms that allow models to self-regulate thought transitions dynamically. Instead of applying a fixed penalty, these mechanisms could adjust the penalty strength based on context, uncertainty, or confidence in a reasoning path. For example: a model could detect when a thought is underdeveloped and automatically reinforce its exploration before considering alternatives.
Such approaches could further improve efficiency and accuracy by tailoring reasoning depth to the complexity of each problem, bringing LLMs closer to human-like adaptive thinking.