
Understanding Distributed Training
A practical look at data parallelism, model parallelism, and real-world systems

Introduction
Hello everyone! Over the past few days, I’ve been reflecting on one of the most important lessons from building enterprise ML systems: scaling ML systems forces you to rethink almost every assumption.
As datasets grow and models become more complex, many of the assumptions that work in small-scale experimentation break down. That’s why I’ve decided to dedicate the next few posts to key concepts you need to understand when building large-scale machine learning systems.
Today’s post focuses on distributed training.
Why Distributed Training Matters
When building models at scale, two things tend to grow rapidly:
The size of the dataset
The complexity of the model architecture
On top of that, real-world ML systems require continuous retraining to stay relevant, whether due to data drift, changing user behaviour, or evolving business requirements.
This makes training slower, more expensive and harder to operationalize
This is where distributed training comes in.
Distributed training is a technique used to parallelize model training across multiple compute resources (e.g., GPUs or machines) to significantly reduce training time and enable scaling.
The two primary approaches are:
Data Parallelism
Model Parallelism
Data Parallelism
Data parallelism involves splitting the dataset into smaller chunks and processing those chunks in parallel across multiple GPUs or machines. Each worker trains a copy of the model on its subset of data.
When is it used?
Data parallelism is typically used when:
The dataset is too large to fit into a single GPU’s memory
Training time becomes a bottleneck
The model itself can fit within a single GPU, but the data cannot
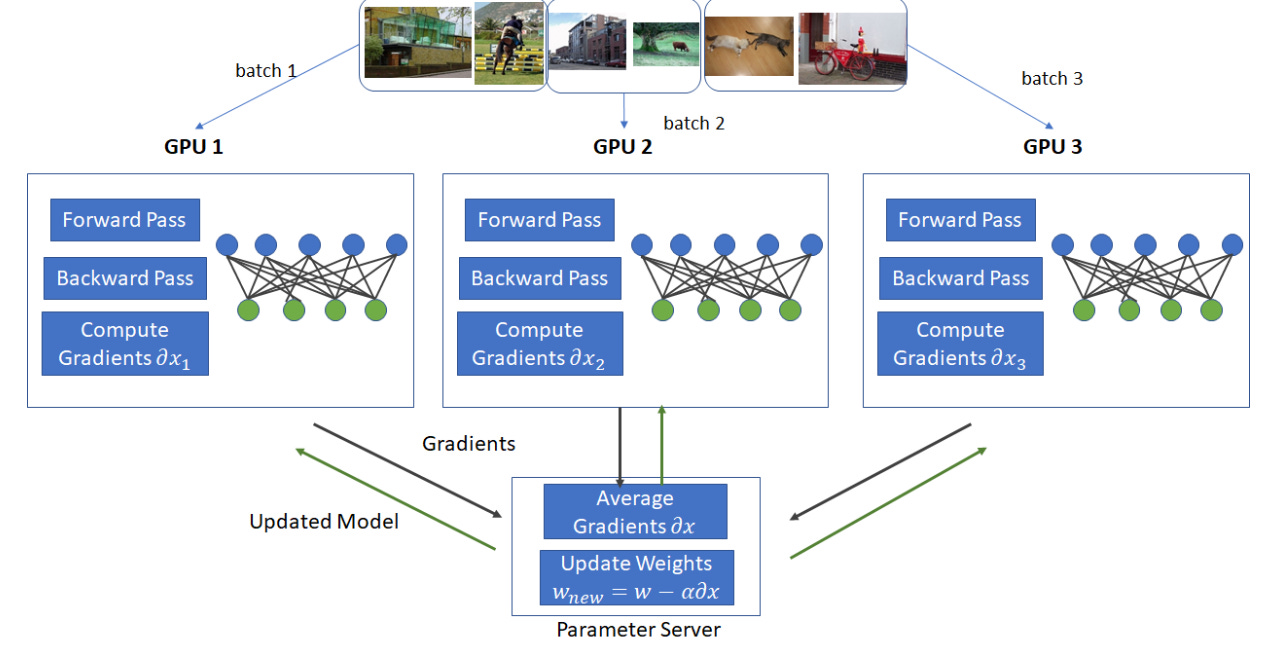
How it works
The dataset is divided into smaller batches
Each GPU receives a different batch
Each GPU performs a forward pass and backward pass independently
Gradients are aggregated (synchronized) across GPUs
The model parameters are updated consistently across all workers
This approach is widely used because it is relatively simple and scales well.
Model Parallelism
Model parallelism involves splitting the model itself across multiple GPUs, instead of splitting the data.
Each GPU is responsible for computing a different part of the model.
When is it used?
Model parallelism is useful when:
The model is too large to fit into a single GPU’s memory
You are working with very large architectures (e.g., large language models, massive transformers)
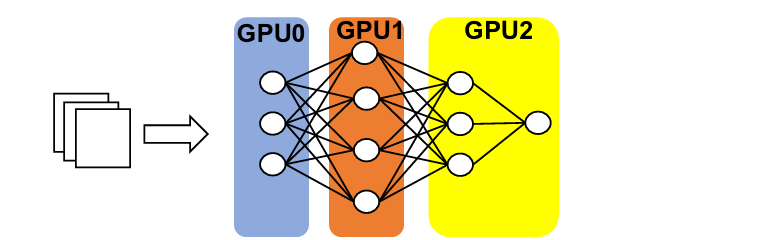
How it works
The model is partitioned into different components (layers or blocks)
Each GPU handles a portion of the model
Data flows sequentially through these partitions
Intermediate outputs are passed between GPUs during forward and backward passes
How Databricks Applies Distributed Training in Practice
Databricks helped a pilot company scale large-scale forecasting models, where the goal was to predict demand across thousands of products.
This setup reflects the challenges we discussed earlier:
Large volumes of historical data
Many parallel training tasks
A need for faster retraining cycles
Data Parallelism in the Pipeline with Apache Spark
A key bottleneck in forecasting systems is preparing the data.
Using Apache Spark, Databricks was able to apply data parallelism at the pipeline level:
Data was split into distributed partitions
Feature engineering (lags, rolling windows, aggregations) ran in parallel
Thousands of product-level time series were processed simultaneously
Scaling Training Workloads with Ray
Once the data was ready, the challenge shifted to training models efficiently.
Instead of training a single large model, the system trained many models in parallel (e.g., one per product or segment).
With Ray:
Resources were dynamically allocated across training jobs
Tasks could request fractional compute (e.g.,
0.5 CPU, shared GPU usage)Multiple models were trained concurrently without wasting resources
This allowed the system to scale beyond simple data parallelism and efficiently handle many parallel training workloads.
Final Thoughts
Distributed training is no longer optional when working with modern ML systems. It’s a foundational capability.
A good rule of thumb:
Start with data parallelism (simpler, widely applicable)
Move to model parallelism when your model size demands it
Combine both for true large-scale systems
In the next post, I’ll dive into another key concept for scaling ML systems: identifying compute resources for processing, training and inference.