
RLHF in Action
A deep dive into how RL with human feedback works, how PPO optimizes models, and how industry is applying it at scale.

Introduction
Welcome to Week 2 of the Reinforcement Learning Series! This week, we’re diving into how RLHF works including a closer look at a well-known abbreviation you’ve probably seen everywhere: PPO. I’ll also explore how Anthropic applies RLHF in practice, showing how human feedback shapes smarter, safer AI.
Reinforcement Learning with Human Feedback (RLHF) has become one of the most transformative techniques in aligning large language models (LLMs) with human values and preferences. In essence, RLHF is how AI systems learn not just to generate text, but to generate helpful, honest, and harmless text.
The goal of RLHF is to refine a pre-trained model so that its outputs align with what humans consider “good” responses whether that means being accurate, polite, creative, or safe.
What Goes Into RLHF
The process begins with three key inputs:
A pre-trained model typically trained with supervised learning on large text corpora.
A reward model trained on human preferences (for example, which of two responses humans prefer).
A reinforcement learning algorithm such as Proximal Policy Optimization (PPO), which updates the base model to maximize the reward.
The Steps of RLHF
Supervised fine-tuning (SFT): Start with a large language model and fine-tune it on a curated dataset of human-written or high-quality responses.
Reward modelling: Collect human feedback by having annotators rank multiple responses from the model. These rankings train a reward model that scores future outputs.
Reinforcement learning (RL) optimization : Using PPO, the model is updated to maximize the reward signal while maintaining stability (so it doesn’t drift too far from the SFT behaviour).
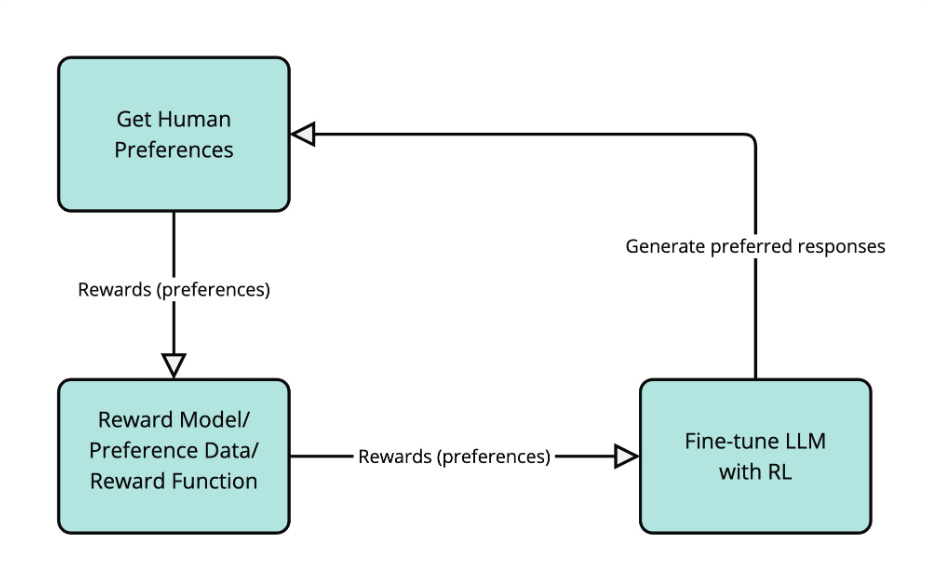
How PPO Fits In
Proximal Policy Optimization (PPO) is the RL algorithm most commonly used in RLHF. PPO adjusts the model’s policy (its output distribution) in small, stable steps. It does this by comparing the new policy to the old one and ensuring updates don’t overshoot.
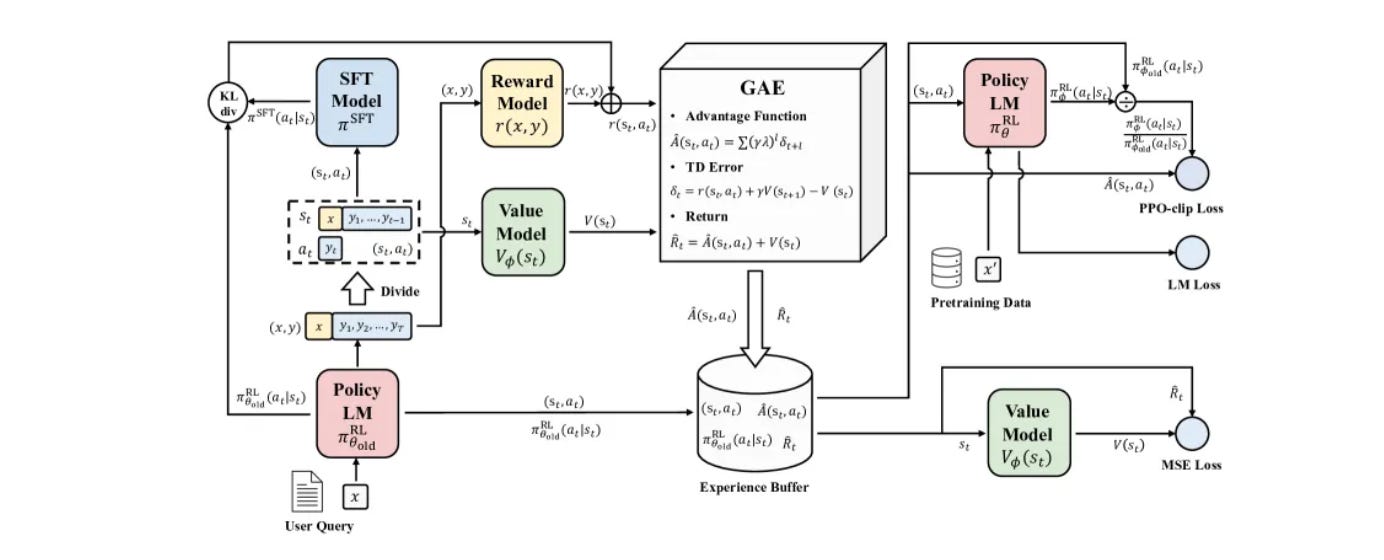
In essence, PPO teaches the model to improve its responses without deviating too far from what it already knows. After the model generates several outputs, each one is scored by a reward model. PPO then adjusts the model’s parameters to increase the probability of producing higher-scoring outputs, but it limits how drastic each update can be.
This is done through a clipped objective function, which prevents large policy changes that might destabilize training. PPO ensures steady, reliable improvement. The result is a model that gradually aligns its behaviour with human or verifiable feedback while maintaining fluency, coherence, and diversity in its responses.
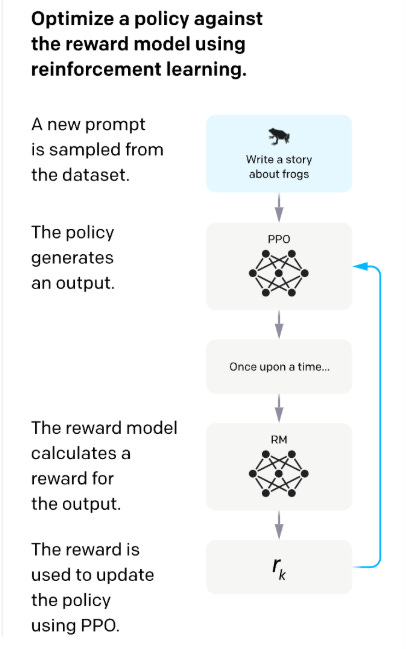
How Anthropic Uses RLHF
Constitutional AI for Claude Models
Anthropic uses a variant of RLHF called Constitutional AI, which enhances traditional RLHF by combining human feedback with a written set of principles, or a “constitution,” that guides what counts as ethical, helpful, or safe behaviour. Instead of relying solely on direct human ratings for every output, the model uses these principles to self-evaluate and critique its own responses, creating an extra layer of automated guidance.
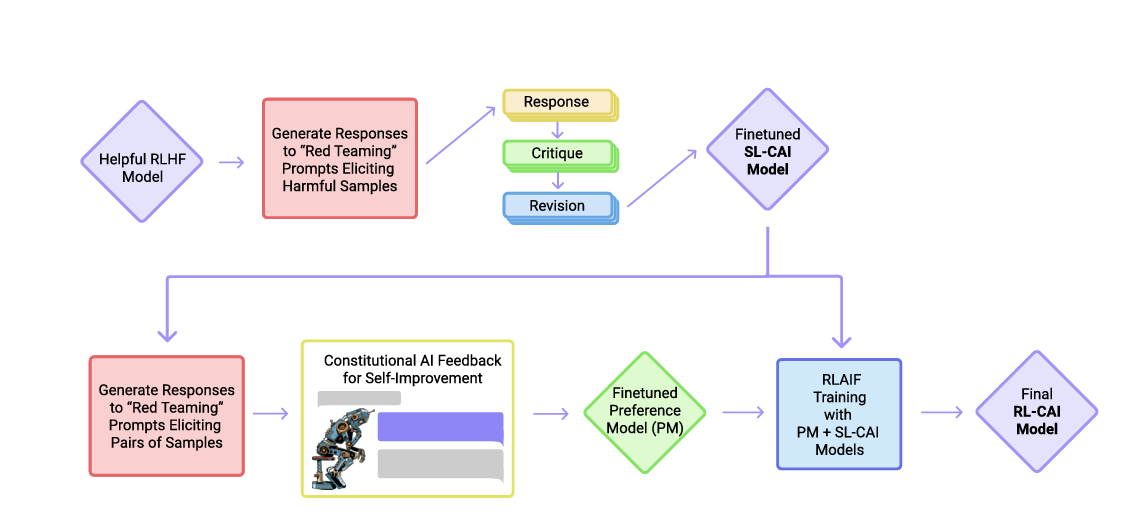
The process begins with the model learning from human demonstrations, just like standard RLHF. Then it iteratively generates outputs, critiques them against the constitution, and refines them using reinforcement learning, including PPO-like updates. This combination of human judgment, codified principles, and RL optimization helps the model align with human values more efficiently.
By embedding these ethical and helpfulness rules directly into the training process, Constitutional AI reduces the dependence on extensive human labelling, scales more effectively, and produces responses that are safer, more consistent, and better aligned with real-world expectations. It is a powerful evolution of RLHF, showing how AI can learn not just from what humans say, but from structured guidance on how to reason about human values.
Conclusion
RLHF has transformed how AI models align with human values, turning raw prediction into thoughtful, helpful outputs. By combining human feedback, reward modelling, and PPO optimization, models learn to balance accuracy, safety, and creativity. Techniques like Constitutional AI show this approach can scale while remaining ethically grounded. As RLHF evolves, it continues to be a cornerstone for building AI systems we can trust and rely on.