
Quantization in Practice
Making Large Models Run Smarter and Faster

What is Quantization?
Quantization, mathematically, is the process of mapping continuous values into a finite set of discrete values. It is widely used in digital signal processing, audio, image compression.
For example: In a digital photo each pixel can store millions of possible colors using 24 bits per pixel. If you apply quantization, you reduce the number of colors the image can use. Instead of allowing 16 million colors, you might limit it to just 256 colors. The photo now takes up much less space, but some subtle details are lost.

The key tradeoff in quantization is between precision and efficiency: using more quantization levels preserves detail but requires more memory and computational resources.
Model Quantization
Artificial neural networks are made up of activation nodes, the connections between them, and parameters such as weights and biases. These weights and biases are typically represented in 32-bit floating point (FP32), which allows for very high precision but is computationally expensive, especially when a model requires millions of multiplications and additions.
Model quantization reduces this burden by mapping these high-precision values into lower-bit formats, such as 16-bit (FP16), 8-bit integers (INT8), or even less. Quantization applies not only to weights but also to activations (the outputs of each layer), ensuring the entire forward pass runs in a more compact numerical space.
The model consumes less memory and runs faster, especially on hardware optimized for low-precision arithmetic, while aiming to maintain as much accuracy as possible.
Floating Point vs Fixed Point Representation
A key distinction here is between floating-point representation and fixed-point (or integer) representation. Floating point allows for a very large dynamic range, but at the cost of more complex hardware and energy use. Fixed-point, on the other hand, uses fewer bits and simpler arithmetic, but with a more limited range. Quantization algorithms bridge this gap by applying scaling factors and calibration technique.
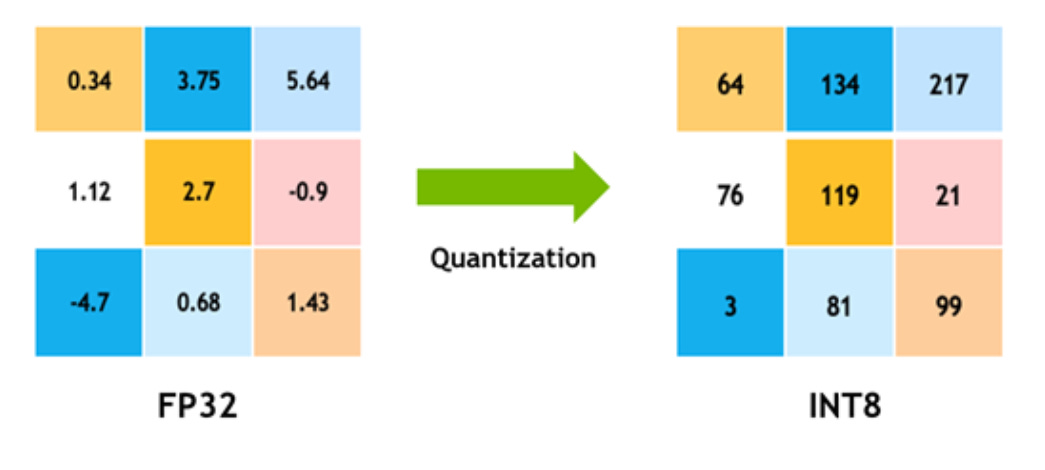
For example, mapping FP32 values to an INT8 range by multiplying or dividing by a learned scale. In practice, this ensures that the compressed values still capture the critical distribution of the data. Techniques such as quantization-aware training (QAT) and post-training quantization with calibration help the model adapt so that small rounding errors don’t accumulate into large accuracy losses. The result is that neural networks can run far more efficiently
Scaling AI with Model Quantization
Model quantization helps businesses cut costs and reach more users by making AI models smaller and faster. A great example is how model quantization allows businesses to enable AI features in smartphones reducing reliance on costly cloud servers while improving response times. This not only lowers infrastructure and energy expenses but also enables AI features in places with limited connectivity.
Apple’s On-Device Foundation Models
Apple’s on-device models even those with around 3 billion parameters are compressed using aggressive quantization techniques. This allows complex models to run with high efficiency in terms of both memory and energy use.
Model Compression Strategy:
Uses a mixed 2-bit and 4-bit configuration, averaging 3.7 bits-per-weight
Achieves same accuracy as uncompressed models.
Optimization Tools & Techniques:
Utilizes Talaria, an interactive tool for latency and power analysis, to guide bit rate selection.
Applies activation quantization and embedding quantization.
Performance on iPhone 15 Pro:
Achieves 0.6 ms time-to-first-token latency per prompt token.
Generates 30 tokens per second.
Conclusion
Apple’s on-device foundation models demonstrate that quantization can be a successful strategy for running larger models efficiently. While there is still ongoing research aimed at improving both accuracy and performance, these results are a testimony to how quantization makes large models accessible. I hope you enjoyed today’s issue and it gave you a clear overview of a term that is often thrown around in discussions about AI. Throughout the rest of August, I’ll be writing about topics that frequently appear online and explore how they’re used ‘in practice’. See you next week!