
Masked Diffusion for Language Models
Using LLaDA to Redefine Language Generation with Masked Diffusion

Autoregressive Modelling: Foundation of Current LLMs
Autoregressive Modelling, also known as the next token prediction paradigm, is a framework where a model predicts the next token in a sequence based on the preceding tokens. Training involves maximizing the probability of each subsequent token given its context.
Autoregressive models exhibit several key properties, including scalability, instruction following, and in-context learning. Additionally, they can be interpreted as lossless data compressors.

While LLMs fall entirely within the domain of generative modeling, recent research challenges the idea that next-token prediction is the only viable approach for achieving generative capabilities and intelligence in LLMs.
LLaDA, a newly introduced large language diffusion model with masking, presents an alternative to traditional autoregressive models, offering a fresh perspective on generative modeling in LLMs.
Diffusion Models
Diffusion models are a class of generative models that create high-quality images, audio, and other data by gradually refining a noisy input. Inspired by thermodynamics, they work by progressively adding noise to data (the forward process) and then learning to reverse this process to generate realistic samples (the reverse process).
Diffusion models are probabilistic and often trained using denoising score matching or variational inference. They have become the backbone of models like Stable Diffusion, DALL·E 2, and Imagen.
Masked Diffusion Models
Masked Diffusion is a novel approach to text generation that differs from traditional autoregressive methods. Instead of generating text left-to-right, it progressively unmasks tokens using principles from diffusion models.
1. Forward Process: Masking
The model systematically replaces tokens with a special [MASK] token.
Each token has:
Probability t of being masked
Probability (1-t) of remaining unchanged.
Once a token is masked, it remains masked throughout the forward process (absorbing state). The masking rate t is sampled from a uniform distribution U(0,1), allowing the model to learn to recover text from different levels of masking.
2. Reverse Process: Unmasking
The model learns to predict masked tokens using bidirectional context (both left and right). Unlike autoregressive models, it does not generate sequentially but rather fills in multiple tokens in parallel.
3. Key Differences from Autoregressive Models
Uses bidirectional context (not just left-to-right)
Non-sequential generation (tokens appear in any order)
Parallel prediction (multiple tokens at once)
Global coherence (entire context influences generation)
Revision capability (earlier tokens can be revised based on later ones)
LLaDA: Large Language Diffusion with Masking
LLaDA leverages a masked diffusion model which constructs a model distribution with bidirectional dependencies and optimize a lower bound of its log-likelihood offering an alternative to LLMs.

Core Approach: Masked Diffusion Modeling
Forward Process (Masking): Tokens in the input sequence x₀ are gradually masked with probability t until fully masked at t = 1.
Reverse Process (Unmasking): The model recovers tokens by predicting the missing words as t moves from 1 to 0.
A mask predictor estimates the masked tokens in parallel, unlike autoregressive models that generate tokens one by one.
Training Process
LLaDA is trained on sequences of 4096 tokens, using 0.13 million H800 GPU hours, similar to other LLMs.
Training involves calculating the cross entropy-loss function for each masked sequence using Monte Carlo for stochastic gradient descent to optimize its loss function.
Fine-tuning (SFT) is applied using prompt-response pairs, improving its ability to follow instructions (e.g., for dialogue tasks).
Performance & Capabilities
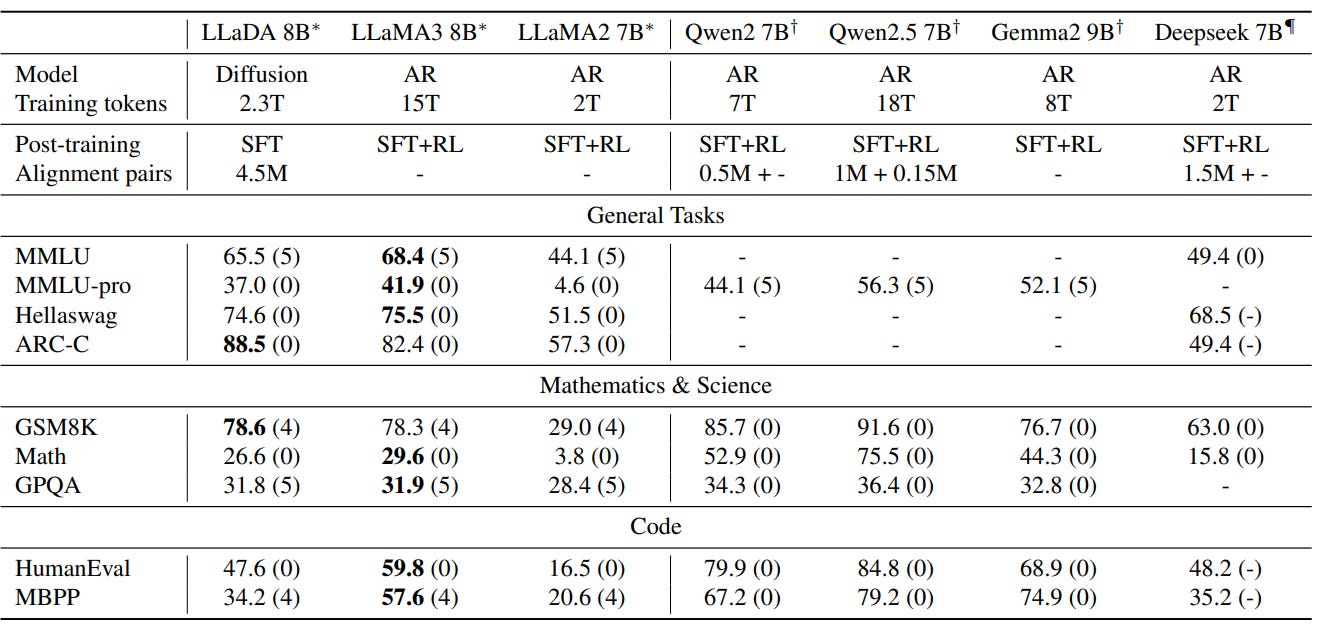
Figure 2: Benchmark Results of Post-Trained LLMs [1] Scalability: Efficiently scales to 1023 FLOPs, matching autoregressive models of the same size.
In-Context Learning: Outperforms LLaMA2 7B and performs on par with LLaMA3 8B in zero-shot and few-shot tasks.
Instruction-Following: After fine-tuning, LLaDA excels in instruction-based tasks, including multi-turn dialogue.
Reversal Reasoning: Unlike traditional LLMs, LLaDA is resistant to the reversal curse and even outperforms GPT-4o in tasks like reversal poem completion.

Conclusion
LLaDA showcases impressive scalability, in-context learning, and instruction-following abilities, rivaling top large language models (LLMs). Additionally, LLaDA brings unique benefits like bidirectional modeling and improved robustness, addressing several limitations of current LLMs. The research also also questions the belief that these capabilities are exclusive to autoregressive models (ARMs).
However, LLaDA's scale is still smaller than leading models, indicating the need for further scaling to fully evaluate its potential. Moreover, LLaDA's capacity to handle multi-modal data remains untested. The effects of LLaDA on prompt tuning techniques and its integration into agent-based systems are yet to be fully explored. Lastly, a thorough examination of post-training for LLaDA could aid in developing systems similar to O1.