


Exploring DeepSeek-R1

Introduction to DeepSeek-R1-Zero
Recently DeepSeek introduced two new LLMS, DeepSeek-R1-Zero and DeepSeek-R1. Both models are using a reinforcement learning focused training approach. These models resulted in impressive performance, comparable to OpenAI’s o1 model and even surpassing it on multiple occasions. The results are a testimony to DeepSeek’s huge step in research towards developing the reasoning capabilities of LLMs without any supervised data, instead focusing on their self-evolution purely through reinforcement learning (RL).
LLMs typically undergo three stages of training which include:
1. Pre-training: The model is trained on a massive dataset using self-supervised learning, typically predicting missing words in sentences.
2. Fine Tuning: The pretrained model is further trained on specific datasets for improved performance in targeted applications (for example: medical or legal texts).
3. Alignment: The model is fine-tuned to align with human preferences, safety, and ethical considerations using human feedback and reinforcement learning techniques. A powerful method for achieving this is Reinforcement Learning from Human Feedback, where the model is trained based on human feedback.
DeepSeek-R1-Zero eliminates the stage of supervised fine tuning. Instead, RL is directly applied to the pre-trained base model (DeepSeek-V3-Base), and this allows the model to explore chain-of-thought for solving complex problems. This means that the model tries to simulate human-like reasoning process by breaking complex tasks into a sequence of logical steps.
Reinforcement Learning and Key Insights
The training template for DeepSeek-R1-Zero guides the base model to first produce a reasoning process followed by the final answer. The supervised fine-tuning stage is eliminated and a rule-based reinforcement learning method is applied.

The reinforcement algorithm used is Group Relative Policy Optimization (GRPO). It extends the proximal policy optimization (RL algorithm designed to improve the stability and efficiency of policy optimization) by incorporating group-based policy updates. For reference, agent is the decision-making entity, action refers to the choices available to the agent, reward is a numerical score given after an action to indicate how good or bad it was, and the policy is the strategy the agent uses to decide actions.
GRPO clusters agents or decision pathways that exhibit similar behavior, allowing for more structured learning. This method improves stability by using relative advantage computation, where an agent’s advantage (the difference between expected and actual rewards) is measured within its group rather than in isolation. By leveraging this group structure, GRPO reduces variance in learning, making policy updates more stable and efficient.
DeepSeek-R1-Zero was trained with a rule-based reward system that mainly consists of two types of rewards:
1. Accuracy Rewards: This evaluates whether the response is correct or not. For example: in the case of a deterministic mathematical problems or a coding problem with test cases, feedback can be generated on the model’s responses.
2. Format Rewards: The model is trained to generate its reasoning explicitly within <think> </think> tags before providing a final answer. Rewards are given based on whether the model correctly follows this structure and whether the reasoning within the tags is useful for arriving at an answer.
One of the key insights from the training process is the demonstration of how RL can lead a model to improve its reasoning capabilities autonomously. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation. Another key insight was the emergence of sophisticated behaviors because of model’s interaction with the reinforcement learning environment. It was observed that the model could revisit and reevaluate its previous steps as well as explore alternative approaches to problem solving.

Figure 1: The average response length of DeepSeek-R1-Zero during RL. It naturally learns to solve reasoning tasks with more thinking time.
Although DeepSeek R1 Zero exhibits powerful reasoning behaviors, it struggles with challenges like poor readability and language mixing. These drawbacks are mitigated by defining a training pipeline that utilizes RL with human-friendly cold-start data (DeepSeek-R1).
DeepSeek R1 Model Training Pipeline
The training pipeline for DeepSeek R1 consists of the following stages:
1. Cold-start data: In this stage a small amount of long chain-of-thought data is used to fine-tune the base model (DeepSeek-V3-Base) as the starting point for RL. The cold-start data is designed to have a readable pattern that includes a summary at the end of each response, filter out responses which are not reader-friendly. This helps observe better performance against DeepSeek-R1-Zero.
2. Reasoning Oriented Reinforcement Learning: After fine-tuning the base model with cold-start data, reinforcement learning is applied (same process as DeepSeek-R1-Zero). In addition to the accuracy reward (for reasoning tasks), a language consistency reward is introduced to mitigate the issue of language mixing when RL prompts include multiple languages. This is calculated as the proportion of target language words in chain-of-thought. The final reward is calculated by summing the accuracy and language consistency reward.
3. Supervised Fine Tuning: Unlike the initial cold-start data (which focused on reasoning), this stage incorporates data from different domains to enhance the model’s capabilities in writing, other general-purpose tasks. The training data consists of 600k reasoning related samples and 200k samples that are unrelated to reasoning. The model was fine-tuned for 2 epochs using the above dataset of about 800k samples.
4. Secondary Reinforcement Learning Stage: The model is trained using a combination of reward signals and diverse prompt distributions. For reasoning data, the rule-based rewards (used for DeepSeek-R1-Zero) are applied to guide the learning process for math, code and logical reasoning domains. For general data, rewards models are applied that capture human preferences in complex scenarios.
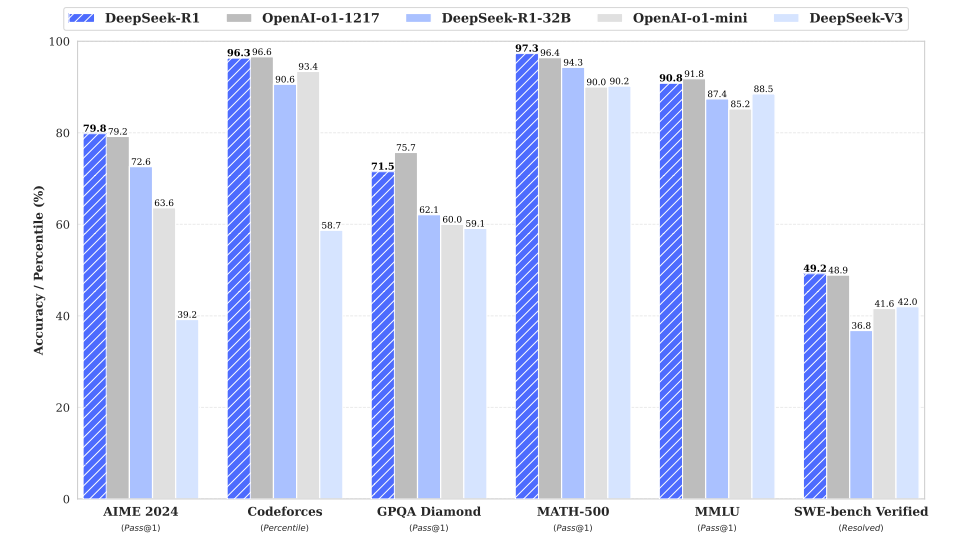
Figure 2: Comparing DeepSeek-R1 with OpenAI o1
DeepSeek-R1 delivers impressive results when assessed against OpenAI’s o1. Moreover, the summary lengths of DeepSeek-R1 are concise indicating that it also avoids length bias during GPT-based evaluations. Additionally, DeepSeek R1 used as the teacher model to generate 800k training samples and fine tune smaller dense models and resulted in promising results when applied for distillation of reasoning capabilities to small dense models.
References: