
Embeddings in Practice
Understanding the role of vector representations in modern AI applications

I’ve recently been diving into literature on recommendation systems and came across a mechanism where recommendations can be scored not just based on user interaction data, but by how similar they are. This spatial relationship becomes possible when the system generates embeddings for each item.
Since then, I’ve noticed that embeddings show up everywhere, especially in LLMs and RAG-based applications. This article explores what embeddings are, where they’re used, and why they matter so much to the direction AI is heading.
What Are Embeddings?
Let’s say we want to represent categorical items in a dataset. For instance, types of fruit in a pricing table. A common approach is one-hot encoding, where each fruit is turned into a binary feature: “1” if it’s present in a row, “0” if not. If you have four fruits, you need four new columns. It’s simple but becomes unwieldy as categories grow.
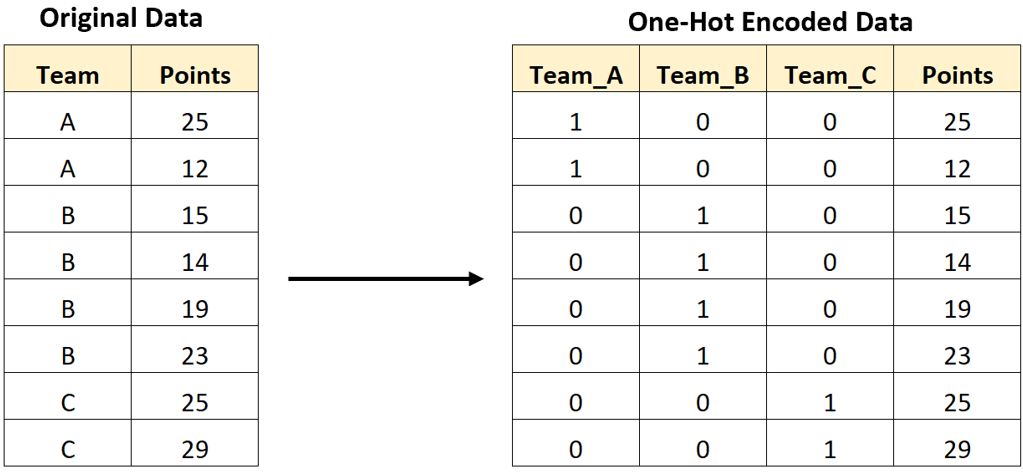
Imagine trying to represent every country, product, or user and suddenly your feature space grows exponentially leading to additional compute, memory costs.
This is where embeddings come in. Rather than using high-dimensional binary vectors, embeddings represent each item as a point in a lower-dimensional space. Instead of dozens or thousands of features, you now have, a 16- or 64-dimensional vector of floating-point numbers (usually between –1 and 1). Each vector captures important relationships between items and the proximity between these vectors represents how similar they are.
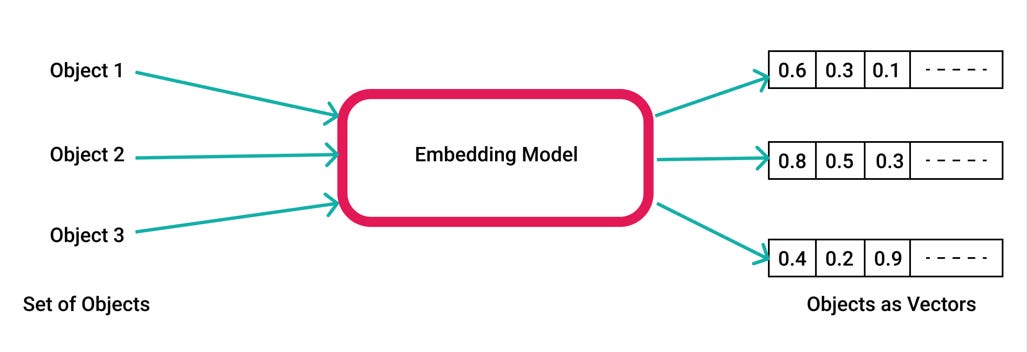
Embedding space is this abstract mathematical “landscape” where items that behave similarly in your data (based on the task at hand) naturally cluster together. You can think of it as compressing knowledge in a way that’s still meaningful for machine learning.
Why Embeddings Differ by Task
Embeddings adapt based on the objective you’re optimizing for. The same item might live in very different parts of the embedding space depending on context.
For example, a model trained to recommend meals based on weather might place “spicy soup” and “hot chocolate” close together because they’re both associated with cold days. But if the goal is to separate dishes by dietary restriction, those same items might land far apart.
This flexibility is one of the reasons embeddings are so powerful. They don’t just encode what an item is, they encode how it relates to other things based on what your model is trying to learn.
Where Embeddings Show Up in AI Applications
Embeddings are everywhere in modern AI. LLMs use them to understand the meaning of words and sentences, search engines use them to retrieve semantically similar results, and recommendation systems use them to match users with relevant content or products. In Retrieval-Augmented Generation (RAG), embeddings are essential for finding contextually relevant documents before generating an answer.
Popular Embedding Models and Frameworks
Several widely-used models and libraries make it easy to generate embeddings for text, images, etc.
word2vec: Early model that introduced the idea of capturing word relationships in vector spaces
BERT-based models: These generate contextual embeddings, meaning the same word can have different embeddings based on context. They’re popular for semantic search and sentence-level tasks.
CLIP: Developed by OpenAI, CLIP maps images and text into the same embedding space, enabling cross-model tasks like image captioning or search.
DeepWalk and Node2Vec: Used for graph data, these models learn embeddings for nodes based on random walks through the graph.
Trade-offs and Limitations
Despite their power, embeddings aren’t without challenges. Interpretability is a major one. Embeddings are abstract and difficult to reverse-engineer or explain in human terms. Additionally, drift can occur when user behavior or upstream data changes, causing embeddings to become stale over time.
Although embedding systems also raise practical engineering concerns such as storage of large vector sets, indexing for fast retrieval, and real-time updating in production pipelines, models today become more reliant on high-quality representations of data.
Embeddings enable generalization across tasks, smooth out sparse inputs, and offer a foundation for building intelligent systems. Embeddings are also central to the future of multimodal systems and to the emerging class of agentic systems that need to retrieve, reason, and act.
References