
Breaking Down Real-Time Search in AI Agents
A Look at Open Deep Search

How do AI agents search in real-time?
If you've used a large language model (LLM) recently, you may have noticed a growing trend: many AI agents now include the ability to search the internet in real time. Platforms like Perplexity and OpenAI have introduced features that combine live web search with the reasoning capabilities of pre-trained LLMs. This integration helps overcome one of the key limitations of traditional LLMs—their static knowledge base—by enabling them to deliver timely, accurate, and contextually relevant responses based on the latest information.
There are four key stages involved in generating a response when combining web search with a language model:
Query Generation: The LLM identifies gaps in its knowledge and formulates relevant search queries
Web Search: These queries are sent to a search engine or a tool that retrieves current information
Retrieval and Reading: The LLM reads and processes the most relevant retrieved content.
Response Generation: Using both its internal knowledge and the retrieved information, the LLM generates a coherent and accurate response.
One of the first questions that came to mind was: how does this system retrieve information from the internet so efficiently?
To achieve fast and efficient retrieval with low latency, the system typically :
Caches results: Reuses recent or frequent queries to avoid redundant searches
Ranks sources: Prioritizes high quality, fast-loading sites.
Limits scope: Uses focused queries and retrieves only top-k results.
Parallelizes requests: Sends multiple queries or fetches content in parallel.
Summarizes early: Extracts and compresses key info quickly before full response generation.
Challenges with Existing Solutions
Advances in search AI have been dominated by proprietary solutions such as Google search, Bing, chatGPT search, and Grok. In particular, Perplexity AI has excelled in this market, even threatening mature leaders. However there are some challenges when it comes to scaling these systems to handle millions of queries.
Retrieval Quality: The challenge is to ensure that retrieved documents are relevant and sufficient to answer the user’s query. Poor retrieval leads to low-quality answers, even if the LLM is strong.
Latency: These systems involve multi-step processes, increasing response time. Long response times can hurt user experience in production systems.
Context Length: LLMs have a limited token window. You must select and compress retrieved content carefully to avoid truncating important context.
Maintaining the retrieval corpus as knowledge changes (e.g. updating or deleting stale data). Keeping sources accurate and timely requires continuous monitoring.
Recent study introduces Open Deep Search which is an open source software that tackles the above challenges and achieves state-of-the-art performance in benchmark evaluations.
Open Deep Search
Open Deep Search is a fully open-source end-to-end deep search system that rivals proprietary AI assistants. Its built entirely on open models and datasets, making it fully reproducible. Additionally its designed for realistic deployment, evaluated with cost and latency in mind. The system can be broken down into two broad stages: Open Search and Open Reasoning.
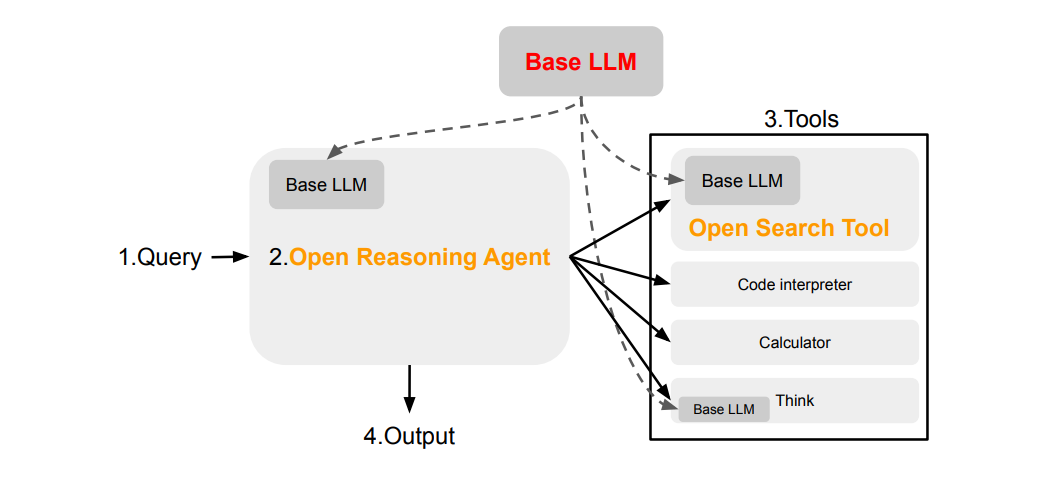
Open Search Agent
This workflow focuses on retrieving relevant information from large scale, open datasets. The purpose of this stage is to build a scalable, interpretable, and high-quality open retrieval pipelines that provides evidence for reasoning. Its key components are:
Query Understanding: Uses open LLMs to rewrite or clarify user queries and enhances search performance by turning vague or complex questions into more retrievable forms.
Retrieval:
In this stage, BM25 (sparse retrieval) for fast keyword based results are used.
Additionally ColBERTv2 (dense retrieval) is used for semantic matching across billions of web documents
Fusion of results from both retrieval types is done to balance precision and coverage
Reranking:
Uses open reranker models like MonoT5 to refine top results
Ensures that the final ranked set of documents is highly relevant to the query
Open Reasoning Agent
Following the retrieval pipeline, this stage focuses on generating accurate and coherent answers using the retrieved documents. The goal is to create an interpretable, open, and modular reasoning engine that aligns generation with retrieval. The key components are:
RAG-style prompting:
The re-ranked documents are concatenated into a prompt
The prompt is given to an open source LLM for answer generation
Open LLMs: The system avoids proprietary APIs and relies solely on publicly available models. The LLM performs grounding, synthesis, and explanation based on retrieved context.
Fact Based Generation: The output includes citations or evidence when possible.
Performance and Challenges
Open Deep Search is competitive with proprietary systems on benchmarks like Natural Questions and ELI5. It shows significant gains over standard RAG baselines by combining high quality retrieval + reranking + open LLMs.

While the Open Deep Search achieves impressive performance, some of the challenges that need work include working towards trade-offs between model size, inference speed and quality. Real-world deployment requires further work on latency and robustness.